The purpose of this white paper is to learn away from 20th century constructs, and introduce an information-based perspective necessary to exploit digital technology in order to orchestrate more climate action.
Written by Georges, cofounder @projetsolaire.

Table of contents
This whitepaper explores the following :
- Success for software start-ups
- The pricing mechanism for marketplaces
- Learning with statistical rigour
- MVP that does not fail
- Data-driven decision-making culture
- Sustaining value creation over time
- Customer is always right
- + Footnotes
Executive summary
This white paper emphasizes the unique challenges faced by software start-ups operating under extreme uncertainty. Unlike traditional businesses, start-ups require a different approach that prioritizes learning what customers truly want and need. Validated learning, backed by empirical data and customer feedback, is the essential measure of progress. By exploring hypotheses, breaking down the founder’s vision, and incorporating price testing, start-ups can navigate uncertainty and build a sustainable enterprise.
Digital microeconomics has changed the supply curve, creating a fundamentally different landscape from traditional industrial microeconomic theory. With digital products offering near-zero marginal costs, perfect replication, and instant distribution, digital platforms leverage these properties to maximize consumer surplus and harness network effects. Profit is now driven by quantity rather than high prices, making user base growth the top priority. By calibrating pricing towards benefiting the demand-side buyers and ensuring a freely functioning pricing mechanism, digital platforms can achieve higher growth, attract supply-side suppliers, and optimize revenues. Transparency, trust, and ongoing testing of pricing are crucial for success in dynamic digital markets.
Business strategy is contingent upon a rationalized vision that guides start-up experimentation, with subsequent hypotheses being empirically tested. The iterative process, inspired by scientific methods, involves the continuous refinement of theories based on feedback between theory and practice. Hypotheses are set based on validating or invalidating the Null Hypothesis, but also surprising findings and emotional responses.
Translating scientific insights into practice requires a data-driven decision-making culture where ideas are evaluated based on scientific merit. Understanding data through customer problems and maintaining high data quality are crucial. The role of the data scientist is essential in ensuring statistically sound and operationally relevant learnings. Balancing theory and practice, entrepreneurs must apply scientific methods to learn from customers and test growth opportunities.
Data analysis plays a crucial role in investigating and refining the models, with the scientist acting both as a sponsor and a critic of the model. Flexibility and the ability to recognize and exploit errors in judgment are essential qualities for a scientist. Statistical rigor becomes important after achieving Product-Market Fit, but the focus should be on practical and optimal understanding rather than excessive elaboration. Sufficient sample sizes and relevant user data are necessary for accurate analysis. Ultimately, sales revenue serves as the quantitative benchmark for achieving Product-Market Fit.
The energy industry is facing significant challenges due to the loss of control in value creation. Regulatory liberalization, technological advancements, and standardization of modular processes have disrupted the industry and created a vast choice space for buyers. For example, photovoltaic solar panels have become a commodity. The concept of value has shifted away from being tied to specific goods or services. Buyers now determine value, which is thus relative and constantly shifting.
To succeed in this dynamic landscape, digital business strategy focuses on expanding the choice space for buyers, offering new dimensions of value, and adapting to buyer needs. Yesterday’s value engine may fail today. Business models alone are insufficient, and there is a need for sustained value creation through innovation and investment in new opportunity platforms. These enable the development of future value engines and provide spaces for flexible entry into new value-creating markets. The value architecture, which explains how value creation is sustained over time, remains constant while strategies evolve based on buyer value. Ultimately, the goal is to earn customer lifetime loyalty through wise digital strategy and consistent design within a single branded experience.
In the context of the energy market, specialized competitors have advantages over integrated ones. Direct customer relationships are key in decentralized energy markets, and our focus at projetsolaire.com is on developing a horizontally-integrated online management solution for KW-scale solar projects.
Bibliography
The following exposition quotes freely and refers to the following sources :
- The Power of the Market ; Milton Friedman (1980)
- Invitation à la Théorie de l’Information (Introduction to Informational Theory) ; Emmanuel Dion (1997)
- Unbundling the Corporation ; John Hagel & Marc Singer (1999)
- Strategies for Two-Sided Markets ; Thomas Eisenmann, Geoffrey Parker, Marshall Van Alstyne (2006)
- The Lean Start-Up ; Eris Ries (2011)
- Value Architectures for Digital Business: Beyond the Business Model ; Peter Keen & Ronald Williams (2013)
- Machine, Platform, Crowd: Harnessing Our Digital Future ; Erik Brynjolfsson, Andrew McFee (2016)
- Economie du Bien Commun (Economics for the Common Good) ; Jean Tirole (2017)
- Financial Management for Technology Start-Ups ; Alnoor Bhimani (2017)
- Создание Экосистемы (Building an Ecosystem) ; Dima Vadkin (2019)
- “Quantitative Methods”, “Statistical Models and Data Analysis”, and “Elementary Data Analytics with R” Department of Statistics of the London School of Economics and Political Sciences (2019)
Success for software start-ups
“There is humility in eagerness to learn”
— John D. Rockefeller
Start-ups are human organisations designed to create new products under conditions of extreme uncertainty. This uncertainty arises from a complete lack of both product and market knowledge [Footnote 1 on Information theory]. Nevertheless, start-ups are catalysts that transform ideas about problems into solutions. Their purpose is to learn how to build a sustainable value creating enterprise that grows.
Software enterprises have no tangible assets on their balance sheet. A digital technology company builds a service that can scale due to technology as opposed to labour hours — companies requiring extra labour hours or material to produce more units of output cannot scale as fast as software [See Footnote 2 on Labour cost drivers]. A digital enterprise needs no extra labour hours to scale, has no non-cash receivables nor payables, and holds no inventory (and inventory risk) on its books.
Previously a good plan, thorough market research, and a timeline (ie. a fat business plan) were perceived as signals that an enterprise would succeed. It is tempting to apply this framework to start-ups too, but that doesn’t work, because start-ups operate with too much uncertainty.
Instead, all effort that is not absolutely necessary for learning what customers want and need should be eliminated. Unfortunately, learning is frustratingly intangible. Demonstrating progress over months (and years) when one is embedded in an environment of extreme uncertainty demands a rigorous method and actionable metrics.
To face uncertainty start-ups must explore and experiment with hypotheses. A hypothesis is a supposition made on the basis of limited evidence as a starting point for further investigation. Such a supposition appears as a Null Hypothesis; with an Alternative Hypothesis if otherwise.
The founder’s vision is actually just a rationalised qualitative conceptual map (ie. theory) that precedes any statistical analytics. Its rationalist not empiricist.
Citation from Descartes’ Discours de la méthode
« … the principal precepts of logic :The first was never to accept anything as true that I did not evidently know it to be so: that is, to carefully avoid haste and prejudice; and to understand nothing more in my judgments than what presented itself so clearly and distinctly to my mind, that I had no occasion to doubt it.
The second, to divide each of the difficulties that I would examine into as many parts as possible and required to best solve them.
The third, to conduct my thoughts in order, beginning with the simplest objects to be known.
And the last, to make everywhere such complete enumerations, and such general reviews, that I was sure of not omitting anything.
… These are long chains of very simple and easy reasons. »
The vision ought to then be broken down into its constituent parts. Contingent causal modelling outlines vision into respective hypotheses of principles, assumptions, logical relationships, technicity, regulatory framework, market trends, and above all customer behaviour.
Validated learning is the essential unit of progress for start-ups: “Validated learning is the process of demonstrating empirically that a team has discovered valuable truths about a start-up’s present and future business prospects. It is more concrete, more accurate, and faster than market forecasting or classical business planning. It is the principal antidote to the lethal problem of achieving failure: successfully executing a plan that leads nowhere”.
Validated learning is backed up by empirical data collected from real customers. As these early adopters interact with the product, they generate feedback (data). This helps in turn gauge interest of customers and enables segmentation of early adopters into groups with similar perceived needs.
Pricing also acts as information capture. Your first product thus also includes price testing. Payments must occur from the get-go (no freemium models!) as this will instantly and directly offer feedback from users. There is no clearer validated learning outcome than a sale.
The pricing mechanism for marketplaces
“There are two kinds of companies, those that work to try to charge more and those that work to charge less. We will be the second” — Jeff Bezos
The supply curve in digital microeconomics is fundamentally different from traditional (industrial) microeconomic theory of the firm. Digital products are free (marginal cost is near zero), perfect (a copy is identical to the original) and instant (distribution is immediate). These properties create a powerful combination.
Digital platforms take advantage of all three characteristics; their marginal cost of access, reproduction and distribution is near zero. Costs are dissociated from revenues : digital platforms have no inventory nor receivables risk.
Thus, the economic interest of a digital platform is to maximise consumer surplus benefit to harness network effects.
π = R - C
Profit (π) is a function of revenue (R) and cost (C).
π = q * (p - cV) - cF
Expanding the equation, profit is a function of price per unit (p) minus variable cost per unit (cV) of all quantity sold (q) subtracting fixed cost (cF).
Digital microeconomics has transformed this equation, however. Prices (p) are low (or can even be free where p=0) and variable costs are lower still [See Footnote 2 on Labour cost drivers]. Fixed costs (cF) are also falling thanks to cloud computing infrastructure and widespread subscription solutions.
Covering fixed costs requires breaking-even through growth of quantity of units sold (q). As operational expenses increase, more units are needed to cover the fixed cost. The unit economics of one extra unit of quantity (q) must therefore contribute greatly to covering fixed cost. The gross profit per unit of quantity, known as contribution margin, is therefore the key metric to measure the unit economics of the business to scale fixed costs.
Thus, value is only captured through quantity (q), as it costs almost nothing to have more of it (assuming favorable contribution margin). Profit is maximized through sales volume and growth. Hence, the first priority is to maximize the user base.
If pricing (and non-pricing standards) is calibrated towards benefitting the demand-side, two things happen. Firstly, expect higher growth from the demand-side. Secondly, the supply-side will always have an incentive to participate. This is known as “cross-side” network effects — if we attract enough “subsidised” buyers, “cash cow” providers will pay us handsomely to reach them. Demand-side driven growth in volume will always drive subscription-based revenues from the supply-side.
Given the combination of properties of digital microeconomics, digital platforms emerge by best executing a freely functioning pricing mechanism. Prices in marketplaces perform three functions: (i) they transmit information, (ii) they provide incentives to adopt methods that are least costly and create most value, (iii) they determine who gets how much from the generated incomes.
A freely functioning and thus efficient price mechanism is determined by today’s and tomorrow’s demand and supply. The price mechanism therefore transmits only important information and only to relevant people; it is made most efficient (real-time, transparent, instant, accurate, etc.) by digital marketplaces. Anything that prevents prices from expressing freely the conditions of demand and supply interferes with the transmission of accurate information.
A price mechanism, if free and efficient to transmit information, ipso facto also provides both an incentive to react to the information and the means to do so. An efficient price mechanism provides incentives for the supply-side to improve their offer within the marketplace in order to charge higher prices. Price transparency allow the supply-side to optimise their pricing based on their current competitiveness; price accuracy allows the supply-side to optimise their cost structure.
Ultimately, an efficient price mechanism allows the demand-side to self-select themselves based on their preferences. The demand curve in turn allows the supply-side to further optimise their offer based on demand-side preferences, and so on.
Parallel to the price mechanism’s informational role, the marketplace also offers the ability for the supply-side to input additional non-price information (signals of quality, timeliness, intangibles, etc.) to communicate their ability to satiate demand-side preferences.
The best suppliers will earn higher income; the worst will have incentives to improve, or adapt their offer, or leave the market; other ambitious suppliers will desire to enter the market. An efficient marketplace emerges.
The marketplace platform defines the standards for entry, for interfaces, and for interactions. A successful digital platform defined the effort and costs to input information, and the emphasis of some communicated information versus other information.
Trust is essential. Pricing must always be transparent and visible. Always remind users of incoming payments and pro-actively inform of price changes; this will also allow preventive risk management of pricing tactics directly from the user. Any price change or premium positioning must be analysed against growth-maximisation priorities. This will include advocated-based aggressive price discounts (whereby marquee users that are especially important to attracting other users pay less).
That is why demand-side B2C customers should never be charged directly on a digital platform (the demand-side is “subsidized”). This is essential as their presence is highly valued when attracted in volume by the “cash-cow” supply-side customers (B2B professionals).
Obviously, pricing cannot not be static and will evolve. It is essential to continue testing pricing strategies to continue learning about our customers.
Learning with statistical rigour
“The question is harder than the answer. If you can properly phrase the question, the answer is the easy part”
— Elon Musk
Business strategy can be defined as a contingency-based vision, resting on a set of causal hypotheses that make predictions about what value is for buyers, and what is contingent to this value creation. Just as scientific experimentation is informed by theory, start-up experimentation is guided by the start-up’s rationalised vision. These hypotheses are subsequently tested empirically.
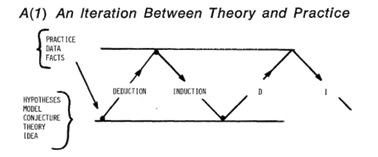
Scientific methods are means whereby learning is achieved, not by mere theoretical speculation on the one hand, nor by the undirected accumulation of practical facts on the other, but rather by a motivated iteration between theory and practice such as is illustrated in Figure A (1).
Matters of fact can lead to a tentative theory (initially through secondary desk research only). Deductions from this tentative theory may be found to be discrepant with certain known or specially acquired facts. These discrepancies can then induce a modified, or in some cases a different, theory. Deductions made from the modified theory may now in turn conflict with the facts, and so on. This main iteration is accompanied by many simultaneous sub-iterations in reality.
On this view efficient scientific iteration evidently requires unhampered feedback (primary field research “on the ground”). The iterative scheme is shown as a feedback loop in Figure A (2).
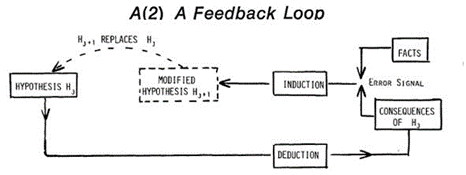
In any feedback loop it is, of course, the error signal — for example, the discrepancy between what your tentative theory suggests should be and what practice reveals — that can produce learning.
Data analysis, a sub-iteration in the process of investigation, is illustrated here:

In the inferential stage, the scientist acts as a sponsor for the model. Conditional on the assumption of its truth they select the best statistical procedures for analysis of the data. These are stochastic : to allow for uncertainty, variables are assumed to be random distributions that contain error terms.
Having completed the analysis, however, the scientist must switch their role from sponsor to critic, which depends now on the contrary assumption that the model may be faulty in suspected or unsuspected ways. The scientist applies appropriate diagnostic checks, involving various kinds of residual analysis if possible.
The point is that a good scientist must have the flexibility and courage to seek out, recognize, and exploit errors in judgment between own vision and the information : no one must ever fall in love with their own idea!
Statistical rigor [See Footnote 2 on Statistical inference terminology] is obviously not possible prior to Product-Market Fit. That is not the point. Ultimately, all models are incomplete, hence, the scientist cannot obtain a “correct” one by excessive elaborative over-thinking. On the contrary, following Occam Razor, they should seek a practical and optimal understanding of phenomena. Just as the ability to devise simple but evocative models is the signature of the great scientist; so is over-elaboration and over-parameterization (overfitting) often the mark of mediocrity.
Sufficient sample sizes must be achieved — each of which must at minimum be superior to 30 (to satisfy normality condition necessary for CLT). Note that A/B (causal) testing requires two samples (thus 30*2=60). Rudimentary but rigorous statistical modelling and data analytics, which require training sets and testing sets where the latter is greater than the former, require a minimum of
per training plus testing set. Samples must be relevant to any given customer problem, and thus total number of users must be greater still.
Hypotheses must nevertheless be set. Prior to Product-Market Fit most detail must be recorded when users say the following:
- Something that validates the Null Hypothesis — you’re right
- Something that invalidates the Null Hypothesis — you’re wrong
- Anything that is surprising (an unknown unknown)
- Anything full of emotion — source of new hypotheses
Although imperfect as partial, the ultimate quantitative benchmark for Product-Market Fit is sales revenue.
MVP that does not fail
“If you’re not embarrassed by your first product release, you’ve released it too late”
— Reid Hoffman
Experimentation is more than just a theoretical inquiry; it is also a first product. Although courage of conviction is important, the market is the ultimate judge. Extreme uncertainty dissipates only once Product-Market Fit — the degree to which a product satisfies a strong market (ie. customer) demand — is achieved. Start-ups need a mechanism for internalising new information they get from the external world and from its own internal operations to test and learn vis-à-vis its vision.
First, break down your vision into two mega-hypotheses:
1) Value Hypothesis: tests whether a product delivers value to customers once they are using it. Determined by discrete choice modelling, which answers “Among people who used our product (or competitor), what is the significance of each feature compared to other features? and thus their willingness to pay for each?”.
2) Growth Hypothesis: tests how new customers will discover the product; including exact first touchpoint determination. Determined by cohort analysis, which answers “Among people who used our product, how many exhibited each behaviour critical to engine of growth (eg. email submission, account creation, signatures) on daily, weekly or monthly basis?”.
The MVP (Minimum Viable Product) helps start-ups start the process of learning as quickly as possible to answer: “What is required to get customers to engage with the product and tell others about it?”. To that end, it must demonstrate clear causal relations and measure respective impacts between the vision, product, and customers.
Validation is “knowing whether the story was a good idea to have been done in the first place”, where story is customer perspective of a given feature. Additional features — beyond what early adopters demand — are a waste of effort, cash and time. Early adopters use their imagination to fill in the missing features.
Discovering the Job To Be Done — what pain is driving behaviour of customers — can be quantitative (A/B testing, cohort funnel analysis) and qualitative (projective techniques, psychographic feedback).
Understanding the Job To Be Done helps discover the Minimum Viable Segment (MVS) to the MVP — the optimal beachhead sub-segment. The beachhead is the initially targeted, geographically constrained, (paying) customer segment. It helps achieve cashflow break-even (minimum) and maximise validated learning holistically (viable). It is optimal if it is highly interactive (with important word-of-mouth).
Once the critical Value Hypotheses and the Growth Hypotheses are tested and validated, customers suddenly start using the MVP pro-actively. Delightful use of a product that solves real problems well catalyses word-of-mouth. An exponential impact follows as new customers spread your product to others.
The MVP is developed until MVP-MVS Fit is achieved.
Product-Market Fit occurs, and positive net cashflow ensues.
Data-driven decision-making culture
“The wise always learn many things from their enemies”
— Aristophanes
Translating scientific insights into practice is a sociological as much as a technical question (ie. All about team culture).
Truth seeking requires top-down and enforced data-driven decision-making culture. Everyone must accept that any and every idea (including their own) must be killed if the data indicates so.
Evaluation of ideas by scientific merit is rarely achieved and can always lapse: but it must be integral. Only then can informed decisions be made using the data.
Data itself must only be understood through customer problems (which are central to any business problem) whether basic or within the CRISP-DM. Key processes and assumptions in data preparation must be centralised and standardized around the customer from inception. First account creations allow you to start data collection of an expanding number of attributes per customer profile. This competitive advantage over incumbents can only be exploited if (1) data-driven decision-making is the norm and (2) data is always well organised.
Tendency to redefine the problem rather than solve it, characterized by development of theoretical models that seldom relate to the reality is typical once the purpose of the statistical problem is lost. The data scientist (if any) have an essential responsibility to the technology team as that of an architect, with the crucial task of ensuring that learnings are statistically sound and operationally relevant.
Prior to complex machine-learning analytics however, database systems must be of standard quality. Data quality is a key enabler of analysis. Transparent access to relevant information by any teammate to the internal information system is essential. The scientist must always include exact assumptions with causal conclusions, and always be modifiable with sensitivity analysis. Someone must be responsible for fundamental information quality and database management to support data-driven decision-making.
A proper balance of theory and practice is needed. Most important, entrepreneurs must learn how to be good scientists; a talent which has to be acquired with experience and by example. Scientific methods must be applied to learn from customers, experiment with growth opportunities, and test future value engines.
Sustaining value creation over time
“Progress, in capitalist society, means turmoil”
— Joseph Schumpeter
The energy industry is failing to adapt to its loss of control in value creation. Three intersecting, historical and non-cyclical forces of disturbance — regulatory liberalisation, technological advances, and standardisation of interfaces of modular processes — are opening up the choice space.
The choice space is a product range defined by a buyer’s perceived value — with respective customer journeys and each with their own marketplace aggregation and respective features. Value has ceased to be a function of the good or service, is neither stable nor fixed, and is less and less under control of providers. Global supply chains of products have indeed led to wide-spread commoditisation of clean technologies.
Value is entirely a function of choice space within digital ecosystems. Buyers are demanding a choice space that satisfies their demand. The realities of value are: (i) buyers determine value, hence (ii) value is always relative and shifting, (iii) companies adapt to ecosystems, and (iv) the entrepreneur offers new dimensions of value.
Value is therefore entirely a function of choice space. Value creation is therefore entirely a function of the expansion of the choice space. Its value architecture must accommodate ever-continuing shifts in value.
Digital business strategy aims to exploit jolts and fissures that open the choice space within an industry’s status quo. The entrepreneur offers new dimensions of value by expanding the choice space for customers. In this context, buyers’ dimensions of value increasingly move from being centred on features and towards standardised interfaces and ecosystems built on a single branded customer experience (think apps/iPhone/iOS/Apple ecosystem).
Business models are therefore not an end point, but an interim model in time that fails to account for sustained value creation as the buyers’ dimensions of value shift. There is a need to constantly follow buyer needs and wants and sustain value creation.
Wise digital strategy is always defined by buyer’s ever-shifting value and thus guided by an abstracted “value architecture”.
Thus, the fixed “business model pitch” is replaced by a value narrative (VN), placing more emphasis on the future opportunities as well as (external) stakeholders. Today’s real value generating activities, the value engine (VE), are both innovations from industry status quo and emphasise cost reductions (hence primarily concerned with cost efficiency and quality).
Yet, there is a continued need to evolve the value engine to adapt to shifts in the choice space.
Opportunity platforms (OP) are practices that identify opportunities to be seized upon when they present themselves. There is a need to design innovation and invest in the unknown to respond quickly to shifts in the choice space. Opportunity platforms include development of a purpose-built enterprise information system, standardised and duplicable marketplace aggregating software, and a modular and scalable data architecture.
Spaces for teams to develop opportunity platforms enable the next value engines. Opportunity platforms are initiatives for flexible (independently adaptable) entrance into new markets with low risk and low cost, through the redeployment of capabilities and a new value narrative.
The below diagram summarises how digital business strategy evolves over time :
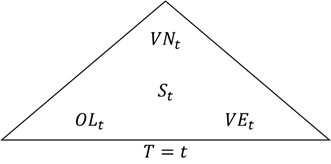
Where (t) is a specific time in (T) ;
(VN_t) is the Value Narrative at time (t) that replaces only exists as a fixed snapshot in time (within a given pitchbook) and evolves over time ;
(VE_t) is the Value Engine at time (t), and is the sum of (VE_t-1) as well as (OP_t-1) ;
(OP_t) is the Opportunity Platform at time (t), that drives (VE_t+1) ; and
(S_t) is the digital strategy at time (t) for time (t+1), that determines the direction for (VE_t) and (VE_t+1) and (OP_t) and (OP_t+1).
In digital microeconomic environments, the product & growth strategy evolves over time. Today’s value engines may be gone tomorrow, and tomorrow’s opportunity platforms are unknown. Tomorrow’s value engines are to be built upon today’s opportunity platforms. The entrepreneur pitches a clear value narrative that overcomes the (time-based) complexity.
Value architecture is the economic logic that explains how ever-shifting value creation is sustained over time. The value architecture *never* changes although the strategy (and by consequence the three elements of the value architecture) do.
Expanding the choice space — and thus orchestrating an increasing number of customer journeys, each with their own marketplace aggregators and respective features — requires innovation via interface and is heavily dependent on simple and consistent design.
This value architecture is designed to earn customer’s lifetime loyalty over time. That is precisely the long-run opportunity of digital strategy.
Customer is always right
“Never stop thinking about how to delight your customers. Not to satisfy them, but to delight them…no enterprise ever failed that had millions of delighted customers. And you start with one, and you get them one at a time”
— Warren Buffett
Businesses consist of (one or more) three functions — (1) customer relationship, (2) product innovation, and (3) infrastructure. Although organisationally intertwined, these are economically and culturally different. Each play different roles, employ different people, and have different imperatives.
Customer relationships demand significant upfront investments; tasks are service-oriented to achieve consistent cash inflows; profit depends on economies of scope (adding-on complements to satisfy customers). The urgency to achieve economies of scope means that businesses based on customer relationships naturally seek to offer a customer as many services as possible. It is often in their interests to create highly customized offerings to maximize sales.
Businesses focused on customer relationships economic imperatives lead to an intently service-oriented culture. When a customer calls, people in these businesses seek to respond to the customer’s needs above all else. They spend a lot of time interacting with customers — and they develop a sophisticated feel for customers’ requirements and preferences, even at the individual level, that makes them better than their competition.
In the context of wide scope of offerings, digital platforms need the design of a single (thus branded) customer experience. A single and coherent brand identity that is both trusted and beautiful is therefore critical to digital business strategy.
These priorities conflict with principles of speed and scale that innovation and infrastructure necessitate. Scope, speed, and scale cannot be optimized simultaneously. Goal incongruence emerges when the three are bundled.
While traditional corporates strive to keep their core processes bundled together, highly specialized competitors are emerging that can optimise the particular activities they perform. Since they don’t have to make compromises, these specialists have enormous advantages over integrated companies.

Given the combination of properties of digital microeconomics, necessity of economies of scope to satiate the demand-side, only a few big infomediaries are possible in any given consumer market. An infomediary is a business whose rich store of customer information — detailed customer profiles through a trusted brand –enable it to control cashflow across the informational ecosystem.
Since :
1. Buyers hate multi-homing, when users have to use multiple ecosystems,
2. Positive and strong “cross-side” network effects exist between customers and providers,
3. Customers don’t have strong preferences for special minute-features in an economies of scope markets,
the necessity to become an infomediary is critical for survival in the looming “winner-takes-all” competitive dynamic of digital markets.
Becoming the standard (ie. best) within the broader industry for any given direct customer solution, as well as for the subsequent operations (winning in the “front” and in the “back”), is the recipe for becoming a market leader.
Unlike centralised and top-down unidirectional energy utilities (or large process-oriented and third-party leads purchasing energy operators), our strategic focus will always remain the creation of direct customer relationships. Why? Because the greatest value creation within the growing decentralised energy markets is in “solving the last mile problem”. The link in this value chain with the most potential is the end-user and their energy.
And that is why we are developing a horizontally integrated, end-to-end, online management solution for KW-scale solar projects. Founded on our strong brand and values, projetsolaire.com will be France’s first community platform orchestrating solar actors for project owners.
[Footnote 1] Information theory
Knowledge is reasoned information, where information is a unit for which uncertainty is halved, where uncertainty is measured by entropy :
Entropy = - ∑ [(n, i=1) ( p_i * log p_i )]
where (p) is probability (if at all calculatable).
[Footnote 2] On labour cost drivers
Labour hours are a cost driver that often represents a fixed cost (cF) of payroll. Labour as a fixed cost can have a short or long relevant range.
Labour that builds software & systems (ie. capital) translates to a great quantity of output per unit of labour (namely a software engineer overseeing great quantities of users) ; the fixed cost is fixed over greater quantities. Thus, the fixed cost has a long relevant range.
If labour does not build capital, but is an input in an operational function to output units of quantity, fixed costs are needed to increase regularly with each increase in quantity (q). Growth in quantity of output requires growth in labour. Thus, “manual” labour becomes at best a fixed cost with a short relevant range, at worse a relatively high variable costs (cV). The same applies to tangible inputs (tangible materials, stock, etc).
As a software technology company aiming to scale, low prices (p) and high variable costs (cV) translate to low contribution margins (= p - cV) to cover fixed costs to develop the technology. Growth is slower as labour is trained and quality of operations is susceptible to human error. Unit economics are bad.
This matters most to small businesses raising venture capital as a software start-up. If you need extra labour hours (or tangible inputs) to increase units of quantity, you’re unit economics are not those of a software technology start-up.
[Footnote 3] Statistical inference terminology
Inferential Statistics : Analysis of sample data to draw inferences about the population from which the sample taken.
Parameter : unknown value to represent population characteristic.
Estimator : rule for calculating an estimate based on sample data and used to approximate parameter.
Estimate : value obtained after calculating an estimator using data from a particular sample.
Sampling must occur from random samples to ensure samples are representative of the population.
Sampling distribution : distribution of the different estimates obtained from each sample.
Point estimate : mean of sampling distribution.
Uncertainty : observations of estimates around point estimate.
Statistical inference requires (i) unbiased estimators with expectation equal to parameter E(x)= μ and (ii) precise estimators with minimal standard deviation of the sampling distribution.
Central Limit Theorem (CLT): for sufficient samples (n > 30) from population with mean (μ) and standard deviation (σ), the sample mean will be approximately normally distributed with mean (μ), and standard deviation (σ/n) regardless of how the population is distributed.
Confidence intervals are used to test whether estimate is statistically significantly different from a specified value.
Confidence intervals convey uncertainty surrounding a point estimate. For 95% significance level, values are (±1.96 * σ) away from mean.
Sampling distribution of the sample mean is normally distributed, such that N(x, SE²), where standard error (SE = σ/√n).
When standard error is unknown, when (σ) is unknown, standard error estimate is (S/√n) given that sample size (n > 30) only ; where
S = √ ( 1/(n-1) * ∑ [(n, i=1) ((x_i - x)²)] )
where (x_i) is unit (i) in sample, and (x) is sample mean.
Margin of error (e) : difference between confidence interval and mean (μ).
Hypothesis Testing is used to examine specific statements about values of population parameters. Hypothesis testing is specified by a null and an alternative hypothesis, (H_0) and (H_1) respectively. Can be one-sided (H_1:x > y) or two-sided (H_1:x =/= y). Null hypothesis (H_0) is rejected if z-statistic is greater than significance level. For 95% significance level, reject (H_0) if (z > 1.96).
This present exposition of informational ecosystems is the explanatory framework behind projetsolaire.com’s offline-to-online (O2O) strategy for solar energy actors first, and for broader clean technologies later.
Written in 2020 during the first Covid lockdown in France.
Chat with the author : click here to book a meeting.
